AI Agent Readiness: Complete 2026 Playbook
AI summaries cut search clicks from 15% to 8%. Learn the agent-readiness checks that help AI systems crawl, cite, use, and convert on your site in 2026.
Share

TL;DR: AI agent readiness is the ability of an AI system to discover, crawl, understand, cite, and safely use your website. In 2025, Pew Research Center found that Google users clicked traditional results in 8% of visits with an AI summary, compared with 15% without one. That makes agent-readiness work a visibility, conversion, and product-access problem.
AI agent readiness is the operational discipline that asks a sharper question than SEO: can an AI system actually use the public surface you built? Search engines rank pages. AI assistants retrieve passages. Agentic browsers and product agents may need metadata, APIs, permissions, and safe actions. If one layer fails, the whole journey breaks.
The shift matters because AI summaries already change behavior. In 2025, Pew Research Center reported that users who saw a Google AI summary clicked a traditional result in 8% of visits, while users without a summary clicked in 15% of visits (Pew Research Center, Do people click on links in Google AI summaries?, 2025). The practical response is not panic. It is measurement.
Use this guide as the hub for the launch cluster. For implementation detail, pair it with the AI crawler access guide, the agent-ready API guide, and the GEO vs SEO strategy guide.
What is AI agent readiness?
AI agent readiness means a website exposes enough public, trusted, machine-readable structure for AI systems to find content, understand entities, cite answers, and perform approved actions. The readiness target is wider than "indexable." It includes crawler policy, HTML quality, structured data, API discovery, OAuth metadata, MCP tools, and conversion forms.
AI agent readiness is a website operations standard for AI retrieval and action. It covers crawler access, static content, schema, API contracts, MCP tools, and conversion flows, so AI systems can cite the site and safely complete user-directed tasks.
The important distinction is intent. A marketing page can be readable by a person and still be weak for agents. A docs page can describe an API and still fail if /openapi.json is missing. A robots policy can protect training data and accidentally block search retrieval. Readiness is the audit that catches those mismatches.

Why does readiness matter after AI Overviews?
Readiness matters because AI answers compress the journey between question and vendor shortlist. Pew's 2025 analysis found that AI summaries nearly halved traditional result-click behavior, from 15% of visits without a summary to 8% with one (Pew Research Center, 2025). If fewer users click, the content that AI systems can retrieve and trust becomes more valuable.
This does not make SEO obsolete. It changes the scoreboard. A useful page should still rank. It should also be extractable, citable, and reachable by AI crawlers. For commercial websites, the end state is not only a citation. It is an action: scan a site, compare plans, request help, start checkout, download a report, or call an API.
| Visibility outcome | Human-era question | Agent-era question | Readiness evidence |
|---|---|---|---|
| Ranking | Can Google find the page? | Can AI retrieval systems access it? | Robots, status codes, sitemap |
| Citation | Is the page authoritative? | Is the answer extractable with sources? | Answer-first sections, tables, sources |
| Action | Can a user complete the task? | Can an agent complete the task with consent? | OpenAPI, MCP, OAuth, forms |
| Conversion | Does the CTA work? | Can the agent preserve user intent? | Tool schema, lead endpoint, report flow |
Which layers should a readiness scan check?
A readiness scan should check five layers: access, meaning, trust, action, and conversion. OpenAI documents separate crawler agents for training, search, and user actions, including GPTBot, OAI-SearchBot, and ChatGPT-User (OpenAI, Overview of OpenAI Crawlers, 2026). Anthropic likewise separates ClaudeBot, Claude-User, and Claude-SearchBot (Anthropic Help Center, 2026).
That separation is the reason a single "allow AI" rule is not enough. Training control, search visibility, and user-directed fetching have different business risks. The scan must show which agent can access which surface, and whether the edge layer quietly blocks a bot that robots.txt appears to allow.
- Access layer: robots.txt, status codes, WAF behavior, bot verification.
- Meaning layer: titles, headings, canonical URLs, schema, tables, readable HTML.
- Trust layer: sources, authorship, freshness, policy pages, crawl transparency.
- Action layer: OpenAPI, API catalog, MCP server card, OAuth metadata.
- Conversion layer: lead form, newsletter capture, report export, follow-up path.
How do you measure AI agent readiness?
Measure readiness as a failing-path report, not as a vanity score. A score helps prioritize, but the useful output is a fix list tied to evidence: the exact robots directive, missing schema field, inaccessible API document, blocked crawler, absent MCP tool, or broken lead action. CanAgentUse is built around that operational model.
A reliable agent-readiness scan reports evidence and remediation for each layer: crawler access, structured content, machine-readable discovery files, API contracts, MCP affordances, and conversion flows. The score should explain what failed and how to verify the fix.
The best audit sequence is simple. First, fetch public files and headers. Second, parse static HTML. Third, test machine-readable routes like /openapi.json, /llms.txt, and .well-known resources. Fourth, map APIs and MCP tools to user journeys. Fifth, rescan after fixes so the team can see what improved.
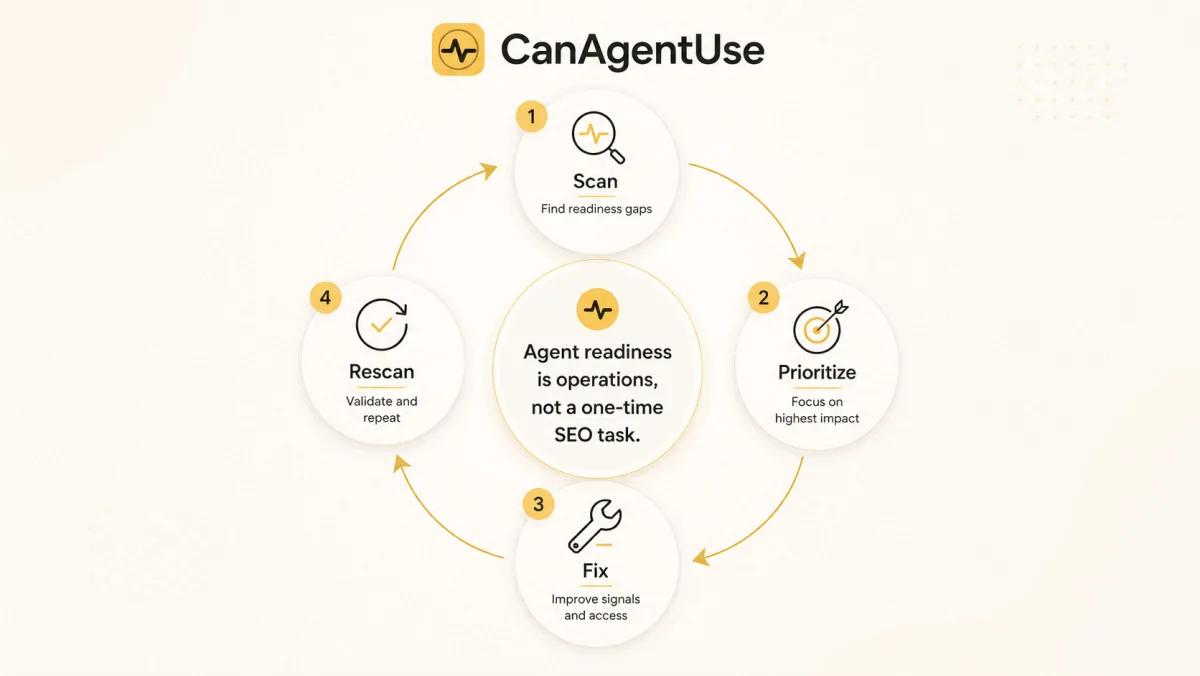
What should teams fix first?
Fix the first blocking layer in the journey. If AI crawlers cannot access the page, do not start with schema polish. If the page is crawlable but the content is vague, fix answer structure. If the content is strong but an agent cannot act, publish the API contract and permission model. Sequence prevents busywork.
The highest-return first fixes are usually:
- Separate training crawlers from search and user-fetch crawlers in policy.
- Confirm WAF and bot tools do not block the agents you want.
- Add answer-first sections with source-backed tables for citation quality.
- Publish
/openapi.jsonand an API catalog for product actions. - Add MCP tools only after the underlying API permissions are clear.
- Put a conversion form below high-intent content and track source paths.
For crawler details, use the AI crawler access guide. For action contracts, use the OpenAPI to MCP guide.
Content changes for AI citations
Content should become easier to extract without becoming shallow. Each major section should open with a direct answer, include a specific source, and use tables or ordered lists where comparison matters. The goal is not keyword density. The goal is a passage that can stand alone when an assistant cites it.
GEO-ready content still needs human quality. Readers stay engaged when the article explains tradeoffs, shows diagrams, gives checklists, and names failure modes. AI systems also benefit from that structure. A well-labeled table or source-backed definition is useful for both people and retrieval systems.
The GEO vs SEO strategy guide turns this into an editorial workflow. Use it to decide which posts need glossary definitions, comparison tables, original experiments, or product screenshots.
FAQ
Is AI agent readiness the same as GEO?
No. GEO focuses on being cited by generative engines. AI agent readiness includes GEO, but also checks whether agents can crawl the site, understand metadata, call APIs, use MCP tools, and complete approved actions. GEO is a visibility surface. Agent readiness is the operating system for that surface.
Do we need MCP before we are agent-ready?
No. MCP is valuable when an agent needs tools, resources, or structured actions. A site can improve readiness first with crawl policy, static HTML, schema, OpenAPI, and clean conversion paths. MCP should come after the product action model is clear.
Should we allow all AI crawlers?
No. Separate training, search indexing, and user-directed fetches. OpenAI, Anthropic, and Perplexity document different agents for different purposes. A practical policy allows the crawlers that support visibility and user intent while blocking training crawlers where the business does not consent.
How often should we rescan?
Rescan after every meaningful change to robots.txt, WAF rules, page templates, schema, OpenAPI, MCP, or lead forms. For active GEO content, monthly scans are a good baseline because crawler documentation and AI search behavior keep changing.
Research sources
- Pew Research Center, Do people click on links in Google AI summaries?, published July 22, 2025, 2026-05-26.
- OpenAI, Overview of OpenAI Crawlers, 2026-05-26.
- Anthropic Help Center, Does Anthropic crawl data from the web?, updated April 7, 2026, 2026-05-26.
- Perplexity, Perplexity Crawlers, 2026-05-26.
- Model Context Protocol, Tools specification, 2026-05-26.
- Google Developers Blog, Announcing the Agent2Agent Protocol, published April 9, 2025, 2026-05-26.
Share