AI Crawler Access: Essential 2026 Playbook
OpenAI, Anthropic, and Perplexity split training, search, and user-fetch bots. Allow AI visibility without losing control of training access or edge security.
Share
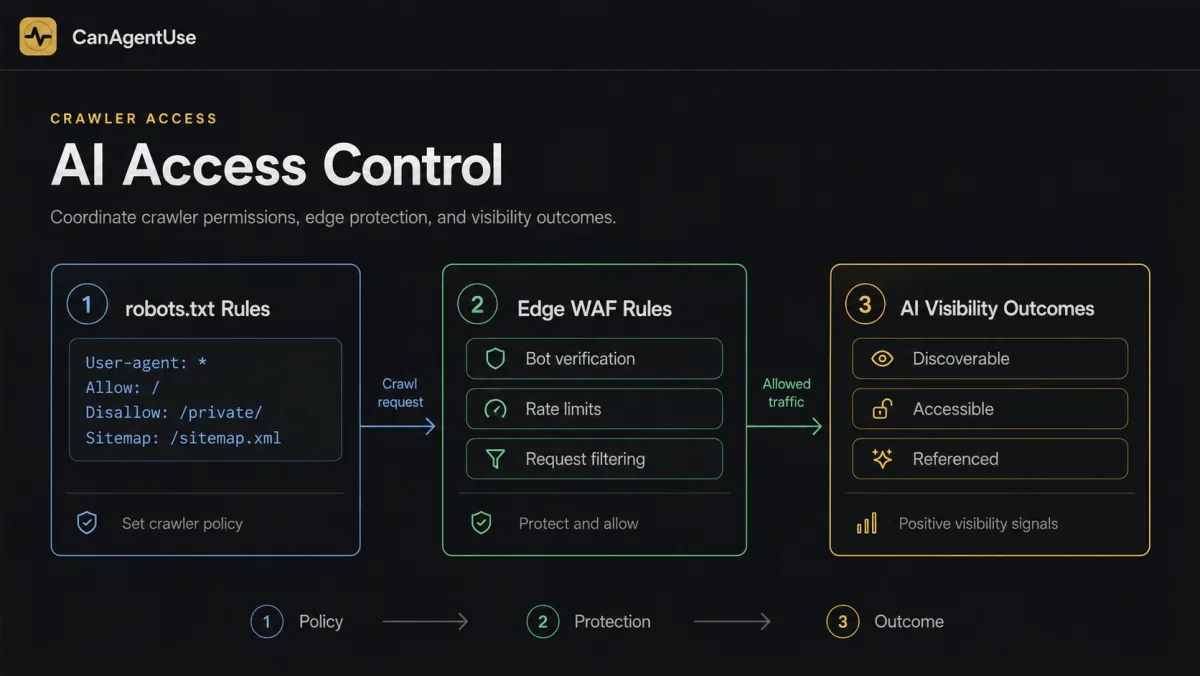
TL;DR: AI crawler access is no longer a single allow-or-block decision. OpenAI, Anthropic, and Perplexity document separate agents for training, search indexing, and user-requested retrieval. A good policy protects training choices while preserving AI search visibility and user-directed access.
AI crawler access is where many GEO programs break. Teams block every AI bot to protect content, then wonder why they do not appear in AI search. Other teams allow everything and lose control over training permissions. The right answer is more precise: separate crawler purpose, verify edge behavior, and monitor logs.
This guide is the technical spoke for the AI agent readiness guide. It also supports the GEO vs SEO strategy, because no citation strategy works when crawlers cannot retrieve the page.
What is AI crawler access?
AI crawler access is the set of robots.txt, firewall, and server decisions that determine whether AI systems can fetch your public pages. In 2026, that access needs purpose-level control. OpenAI documents GPTBot for foundation-model training, OAI-SearchBot for search, and ChatGPT-User for user actions (OpenAI, Overview of OpenAI Crawlers, 2026).
AI crawler access should separate training crawlers, search crawlers, and user-directed fetchers. OpenAI documents different agents for those purposes, including GPTBot, OAI-SearchBot, and ChatGPT-User, so one blanket rule can create the wrong business outcome.
The same pattern appears elsewhere. Anthropic lists ClaudeBot, Claude-User, and Claude-SearchBot as separate robots with different uses (Anthropic Help Center, 2026). Perplexity documents PerplexityBot for search results and Perplexity-User for user actions (Perplexity Crawlers, 2026).
The business risk is usually hidden in defaults. A security team may deploy a managed AI-bot block list that treats every AI user agent the same. A marketing team may publish a GEO brief that assumes Perplexity, Claude, and ChatGPT can fetch every public page. A developer may add a global Disallow: / during staging and forget that production inherited the rule. A crawler audit makes those assumptions visible.
Which bots should you treat differently?
Treat training bots, search bots, and user-fetch bots as different policy classes. Training bots affect whether public content can contribute to future model training. Search bots affect whether AI search systems can discover and cite your site. User-fetch bots support a user who asked an assistant to retrieve a page.
| Policy class | Example agents | Business question | Default posture |
|---|---|---|---|
| Training | GPTBot, ClaudeBot | Do we allow model training on this content? | Case by case |
| Search indexing | OAI-SearchBot, Claude-SearchBot, PerplexityBot | Do we want AI search visibility? | Usually allow public pages |
| User fetch | ChatGPT-User, Claude-User, Perplexity-User | Can a user ask an assistant to read this page? | Usually allow public pages |
| Unknown or spoofed | Generic browsers, unverified bots | Is this legitimate traffic? | Challenge or block |
The exact answer depends on your content type. Public docs, blog posts, pricing pages, and product pages usually benefit from search and user-fetch access. Private, licensed, or paywalled content should be explicit about limits.
For most B2B sites, the sharpest policy is not "allow AI" or "block AI." It is "allow public retrieval, block training where we do not consent, and require authentication for anything account-specific." That gives the brand a path into AI answers while keeping private reports, dashboards, invoices, and account data behind real authorization.

How should robots.txt be written?
Robots.txt should express intent clearly, but it is not the whole enforcement layer. Google Search Central describes robots.txt as a way to tell crawlers which URLs they can request (Google Search Central, Robots.txt Introduction, 2026). AI teams should use it with server logs and WAF rules.
A practical starting point is:
TXTUser-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
This example allows search and user-directed visibility while blocking two training crawlers. It is not universal policy. It is a template for separate decisions.
After changing robots.txt, fetch it from production and inspect the response headers. A common failure is serving the right file on the apex domain while a CDN, locale subdomain, or docs subdomain serves an older file. For multi-domain products, keep a crawler-policy inventory with owner, last update, and intended AI visibility for each host.
If you are also publishing llms.txt, keep the roles separate. The llms.txt and robots.txt publishing guide explains how to use robots.txt for access policy and llms.txt for AI-readable context without confusing crawler control with content guidance.
Why do WAF and CDN rules matter?
WAF and CDN rules matter because robots.txt can look correct while the edge still returns 403, challenges, or bot-fight pages. Perplexity specifically recommends allowing its bots through WAF rules using user-agent and IP checks (Perplexity Crawlers, 2026). Cloudflare also documents verified bot requirements and verification methods (Cloudflare Verified Bots, 2026).
AI crawler policy must be verified at the edge. A robots.txt allow rule does not guarantee visibility if a CDN, WAF, bot tool, or JavaScript challenge blocks OAI-SearchBot, Claude-SearchBot, PerplexityBot, or another legitimate crawler.
The audit should test real HTTP responses from the public internet. Check robots.txt, fetch target pages with crawler-like headers where appropriate, and review logs by user-agent and status code. A readiness score without status-code evidence is not enough.
Edge verification should also distinguish crawler identity from crawler intent. User-agent strings can be spoofed, which is why Perplexity recommends IP range checks in WAF rules. At the same time, a strict IP allow list can fail if the vendor changes ranges and the site never updates its edge configuration. The safest process combines official IP feeds, log monitoring, and a periodic rescan.

What should a crawler access audit include?
A crawler access audit should include policy, transport, and outcome. Policy is what robots.txt says. Transport is what the server returns. Outcome is whether the content can appear in AI search, assistant citations, or user-directed answers.
Use this checklist:
- Confirm robots.txt has explicit rules for major AI agents.
- Confirm sitemap and canonical URLs expose the pages you want cited.
- Test status codes for public pages and source files.
- Inspect WAF, CDN, and bot protection settings.
- Verify official IP ranges for bots that publish them.
- Monitor logs for 403, 401, 429, and challenge responses.
- Rescan after any security or CDN rule change.
CanAgentUse checks this as part of the broader agent-ready website framework, then connects access findings to schema, OpenAPI, MCP, and conversion issues.
For a deeper operational workflow, use the AI crawler audit guide. It covers status-code evidence, WAF behavior, log tables, and the "policy allowed, transport denied" failure pattern.
Crawler access scorecard
Score crawler access with evidence, not assumptions. A strong pass means robots.txt states the intended policy, the target page returns a clean 200 response, the WAF allows the verified bot, and logs show recent successful fetches. A weak pass means policy looks correct but no transport evidence confirms it.
Use four grades. Blocked means the intended crawler receives a disallow, 401, 403, 404, 429, or bot challenge. Ambiguous means policy and transport disagree. Allowed means the crawler can fetch the page but no downstream citation or retrieval test confirms value. Verified means policy, transport, logs, and AI-surface checks all match the intended outcome.
This scoring gives teams a common language. Security can own abuse controls. Growth can own visibility intent. Engineering can own headers, routes, and CDN behavior. Product can decide which pages should be available for user-directed agent tasks.
FAQ
Is blocking GPTBot bad for GEO?
Not necessarily. GPTBot is documented for training, not search visibility. The risky mistake is blocking search or user-fetch bots while thinking you only blocked training. Separate the rules and verify the behavior in logs.
Does robots.txt stop every AI fetch?
No. Robots.txt is a voluntary protocol honored by well-behaved crawlers. It does not replace authentication, paywalls, WAF rules, or server-side authorization. Treat it as a public preference signal, then enforce sensitive access with real controls.
Should Perplexity-User ignore robots.txt?
Perplexity documents Perplexity-User as a user-action agent and says user-requested fetches generally ignore robots.txt rules. That means teams should decide whether public pages can be fetched for a user's answer, then manage sensitive content with authentication rather than robots.txt alone.
How often should crawler rules be reviewed?
Review crawler rules monthly and after any CDN, WAF, bot-management, or site-template change. AI crawler documentation has changed quickly, and a well-intended security change can remove AI visibility overnight.
Research sources
- OpenAI, Overview of OpenAI Crawlers, 2026-05-26.
- Anthropic Help Center, Does Anthropic crawl data from the web?, updated April 7, 2026, 2026-05-26.
- Perplexity, Perplexity Crawlers, 2026-05-26.
- Google Search Central, Robots.txt Introduction, 2026-05-26.
- Cloudflare, Verified Bots, 2026-05-26.
Share